# Spring Boot 整合 ElasticSearch
ElasticSearch 是一个开源的搜索引擎,建立在一个全文搜索引擎库 Apache Lucene 基础之上。(Lucene 可以说是当下最先进、高性能、全功能的搜索引擎库。)
ElasticSearch 使用 Java 编写的,它的内部使用的是 Lucene 做索引与搜索,它的目的是使全文检索变得简单(因为 Lucene 只是个库),通过隐藏 Lucene 的复杂性,取而代之提供了一套简单一致的 RESTful API 。
然而,ElasticSearch 不仅仅是 Lucene 的一层『壳子』,并且也不仅仅只是一个全文搜索引擎,更多的时候它被当作 NoSQL 数据库来使用。
# 1. 版本问题
Spring Data ElasticSearch 和 ElasticSearch 是有对应关系的,不同的版本之间不兼容。
具体版本对应关键见最后。
简而言之:
spring-boot 2.1.x ,仅支持 ES6 ;
pring-boot 2.2.x ,同时支持 ES6 和 ES7 。
# 2. 回顾 Elasticsearch 搜索功能
Elastic Search 搜索没命中的原因无非关系到三点:
中文分词器
document 的字段类型
执行的是 term 查询,还是 match 查询
# 中文分词器的影响
text 类型的字符串数据存储进 Elastic Search 时,会被分词器分词。如果没有指定分词器,那么 Elastic Search 使用的就是默认的 Standard 分词器。
以 张三丰 为例,『默认的分词器』会将其分为 张、三 和 丰(注意,甚至都没有 张三丰!),此时,你以 张三丰 作为条件,进行 term 查询,Elastic Search 会告诉你:没有。因为 张、三 和 丰 都不是 张三丰 。
# document 的字段类型
Elastic Search 中的字符串类型(以前有 String,现在细)分为 text 和 keyword 两种 。
text 类型的字符串数据会被分词器分词,细化为多个 term;而 keyword 类型的字符串数据,则不会被分词器分词,或者说整体就是有且仅有的一个 term 。当然,至于 string 被分词器分为 term 的结果科不科学?给不给力?合不合理?那就是另一码事了,见上文。
以 张三丰 为例(假设使用了 IK 中文分词器),以 text 类型存储时,会被分词器分为 张三丰、张三、三丰、张、三、丰 这好几个 term,也就是说,但凡以上述的哪个 term 作为关键字(例如,张三)进行搜索,都能定位到这条数据。
但是 张三丰 以 keyword 类型存储时,分词器不参与其中工作,张三丰 就是一个整体,张三、三丰、张、三、丰 跟它半毛钱关系都没有。
# term 查询和 match 查询
进行查询时,你提供的查询的关键字/线索,也有可能被分词器进行分词,这取决于你进行的是 term 查询,还是 match 查询。
你进行 term 查询时,你提供的线索,例如 张三丰,不会被分词器分词,也即是说,Elastic Search 就是实实在在地拿 张三丰 作为条件,去数据库中查找数据。
简单来说,你提供的一个查询线索就是一个查询线索。
你进行 match 查询时,你提供的线索,还是 张三丰,分词器会对其分词,也就是说,你以为你是在以 张三丰 为线索进行查询?不,实际上 Elastic Search 是分别以 张三丰、张三、三丰、张、三、丰 这几个,去数据库中查了好几次。
简单来说,你以为你提供的是一个查询线索,实际上是好几个。这样的查询命中自然就高了(至于命中的是不是你想要的,那就是另一个问题了)。
想知道中文字符串被分词器解析出几个词项,可以通过下面命令简介知道:
POST _analyze { "analyzer" : "ik_max_word 或 ik_smart", "text" : "内容" } # 查看某个字段的分词结果 GET 索引名/_doc/指定ID/_termvectors?fields=字段名
# 3. Spring Boot 集成 ElasticSearch
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency><!-- 因为 spring-data-es 要发出 HTTP 请求,所以还需要 spring web 的包 -->
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
老版本配置方式(已被废弃,不再推荐使用)
略。
新版本配置方式(推荐使用)
新的配置方式使用的是 High Level REST Client 的方式来替代之前的 Transport Client 方式,使用的是 HTTP 请求,和 Kibana 一样使用的是 Elasticsearch 的 9200 端口。
这种配置方案中,你使用的不是配置文件,而是自定义配置类:
/** * 你也可以不继承 AbstractElasticsearchConfiguration 类,而将 ESConfig 写成一般的配置类的型式。 * 不过继承 AbstractElasticsearchConfiguration 好处在于,它已经帮我们配置好了 elasticsearchTemplate 直接使用。 * * 在配置文件中配置 spring.elasticsearch.rest.uris=http://localhost:9200 */ @Configuration public class ESConfig extends AbstractElasticsearchConfiguration { @Override public RestHighLevelClient elasticsearchClient() { ClientConfiguration clientConfiguration = ClientConfiguration.builder() .connectedTo("localhost:9200") .build(); return RestClients.create(clientConfiguration).rest(); } }另外,由于 High Level REST Client 的方式是向 Elasticsearch 发出 HTTP 请求,因此无论你用不用得到 spring webmvc,spring-data-elasticsearch 它是一定要用的,所以,这就是为什么你的 pom 依赖中还要加上 spring-webmvc 的依赖。
Elasticsearch 中的 PO 类:
@Document(indexName = "books", shards = 1, replicas = 0)
public class Book {
@Id
@Field(name="id", type = FieldType.Keyword)
private String id;
@Field(name="title", type = FieldType.Text, analyzer = "ik_smart")
private String title;
@Field(name="language", type = FieldType.Keyword)
private String language;
@Field(name="author", type = FieldType.Keyword)
private String author;
@Field(name="price", type = FieldType.Float)
private Float price;
@Field(name = "publish_date", type = FieldType.Date, format = DateFormat.custom, pattern = "yyyy-MM-dd")
private String publishDate;
@Field(name="description", type = FieldType.Text, analyzer = "ik_max_word")
private String description;
// getter / setter
}
@Document :注解会对实体中的所有属性建立索引;
indexName = "books" :表示创建一个名称为 "books" 的索引;
shards = 1 : 表示只使用一个分片;
replicas = 0 : 表示不使用复制备份;
@Field(type = FieldType.Keyword) : 用以指定字段的数据类型。
# 4. 创建操作的 Repository
@Repository
public interface CustomerRepository extends ElasticsearchRepository<Customer, String> {
// SearchHits<Customer> findByAddress(String address);
List<Customer> findByAddress(String address);
Page<Customer> findByAddress(String address, Pageable pageable);
Customer findByUserName(String userName);
int deleteByUserName(String userName);
// 更多示例见笔记的最后
}
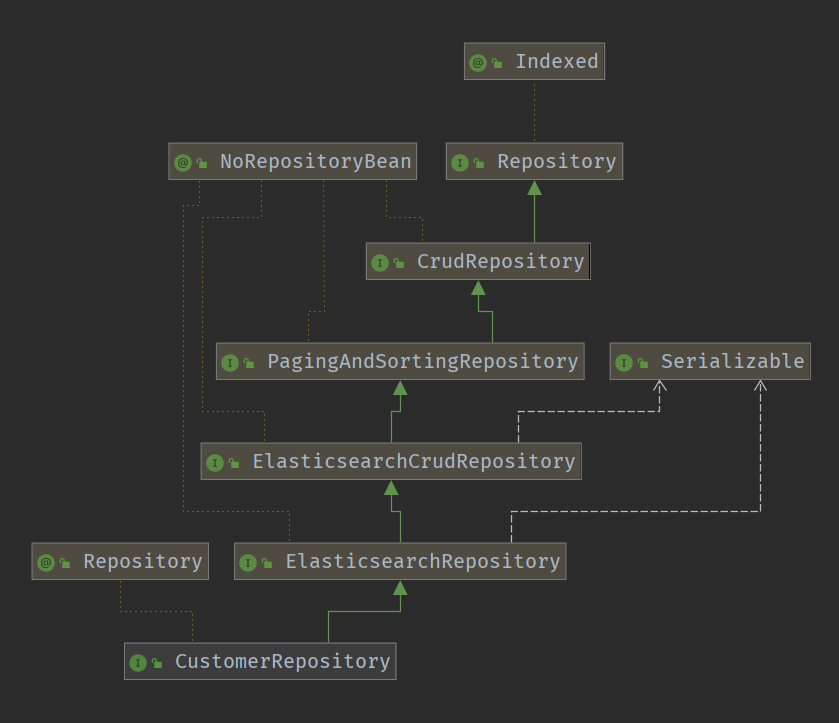
我们自定义的 CustomerRepository 接口,从它的祖先们那里继承了大量的现成的方法,除此之外,它还可以按 spring data 的规则定义特定的方法。
# 5. 测试 CustomerRepository
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest
public class CustomerRepositoryTest {
@Autowired
private CustomerRepository repository;
@Test
public void svaeCustomers() {
repository.save(new Customer("Alice", "湖北武汉", 13));
repository.save(new Customer("Bob", "湖北咸宁", 23));
repository.save(new Customer("Neo", "湖北黄石", 30));
repository.save(new Customer("Summer", "湖北襄阳", 22));
repository.save(new Customer("Tommy", "湖北宜昌", 22));
repository.save(new Customer("Jerry", "湖北荆州", 22));
repository.save(new Customer("关羽", "大意失荆州", 22));
}
}
很显然,上面执行的是插入操作(在此之前还执行了建库建表操作)。
注意:由于我们没有指定 id 属性的值,这意味着,我们希望由 Elasticsearch 来为每一个文档的 id 属性赋值。
不过 JavaBean 中的这个 id 属性是 ES 文档(Document)的元属性 _id ,而不是 id 。从 Kibana 中可以看到 id 属性的值是 null 。
如果我们指定了 id 属性值,那么,文档的原属性 _id 和我们自己的 id 属性值是一样的,都是这个我们指定的这个值。
查询所有
for (Customer customer : repository.findAll()) { log.info("{}", customer); }删除
repository.deleteAll(); repository.deleteByUserName("neo"); // 注意,大小写敏感。修改
Customer customer = repository.findByUserName("Summer"); log.info("{}", customer); customer.setAddress("湖北武汉武昌区"); repository.save(customer); Customer other = repository.findByUserName("Summer"); log.info("{}", other);
# 6. 高级查询
# 分页查询
Spring Data 自带的分页方案:
Pageable pageable = PageRequest.of(0, 2);
Page<Book> books = bookDao.findAll(pageable);
log.info("总共有 {} 条数据", books.getTotalElements());
log.info("总共有 {} 页", books.getTotalPages());
log.info("本页的页号是 {}", books.getNumber());
log.info("本页的页面大小 {}", books.getSize());
log.info("本页的实际数量 {}", books.getContent().size());
// 本页的内容:List<Book>
books.getContent().forEach((item) -> log.debug("{}", item));
# 排序
Spring Data 自带了排序方案:
Sort sort = Sort.by(Sort.Direction.DESC, "price");
Iterable<Book> books = bookDao.findAll(sort);
books.forEach((book) -> log.info("{}", book));
# 使用 @Query 注解
你可以在 Repository 接口的方法上标注 @Query 注解,并明确指定执行怎样的查询:
@Query("{ \"match\" : { \"description\" : \"?0\" }}")
SearchHits<Book> xxx(String content);
注意:
@Query 注解的字符串内容是
{ ... }形式的,不要忘记了大括号。@Query 注解的字符串内容中没有
"query",不要多复制了东西;
假设你传入的 content 参数值为 java ,那么调用上述方法等价于执行了下面的查询:
{
"query": {
"match": { "description": "java" }
}
}
# term 查询
// 不建议使用。官方建议使用上述的 @Query 替代。
QueryBuilder queryBuilder = QueryBuilders.termQuery("description", "java");
Iterable<Book> it = bookDao.search(queryBuilder);
it.forEach((item) -> log.info("{}", item));
# match 查询
// 不建议使用。官方建议使用上述的 @Query 替代。
QueryBuilder queryBuilder = QueryBuilders.matchQuery("description", "java编程");
Iterable<Book> it = bookDao.search(queryBuilder);
it.forEach((item) -> log.info("{}", item));
# 多条件查询
QueryBuilders.boolQuery()QueryBuilders.boolQuery().must():相当于 andQueryBuilders.boolQuery().should():相当于 orQueryBuilders.boolQuery().mustNot():相当于 not
注意,合理的 and 和 or 的嵌套关系,有助于你理清逻辑。建议像 Mybatis 的 Example 对象学习,组织成 (... and ...) or (... and ...) 的形式。
// 不建议使用。官方建议使用上述的 @Query 替代。
QueryBuilder query1 = QueryBuilders.termQuery("", "");
QueryBuilder query2 = QueryBuilders.termQuery("", "");
QueryBuilder query3 = QueryBuilders.termQuery("", "");
QueryBuilder query4 = QueryBuilders.termQuery("", "");
// ... and ...
QueryBuilder all = QueryBuilders.boolQuery()
.must(query1)
.must(query2);
// ... or ...
QueryBuilder all = QueryBuilders.boolQuery()
.should(query1)
.should(query2);
// (... and ...) or (... and ...)
QueryBuilder all = QueryBuilders.boolQuery()
.should(
QueryBuilders.boolQuery()
.must(query1)
.must(query2))
.should(
QueryBuilders.boolQuery()
.must(query3)
.must(query4));
# 7. 附-版本对应关系
Spring Data ElasticSearch 和 ElasticSearch 是有对应关系的,不同的版本之间不兼容。
官网描述的对应关系如下表:
| Spring Boot | Spring Data Elasticsearch | Elasticsearch |
|---|---|---|
| 2.2.x | 3.2.x | 6.8.4 |
| 2.1.x | 3.1.x | 6.2.2 |
| 2.0.x | 3.0.x | 5.5.0 |
注意,Spring Boot(Spring Data Elasticsearch)和 Elasticsearch 的版本匹配问题是网上反映较多的问题一定要注意。以上是官网列出的版本对应关系,但是实施情况好像也并非如此,实际情况比较混乱。
总体而言规则如下:
| spring-data-es / spring-boot | ES7 | ES6 | ES5 |
|---|---|---|---|
| 3.2.x / 2.2.x | 支持 | 支持 | 不支持 |
| 3.1.x / 2.1.x | 不支持 | 支持 | 不支持 |
| 3.0.x / 2.0.x | 不支持 | 支持 | 支持 |
# 8. 示例
And: findByNameAndPrice
{ "query" : { "bool" : { "must" : [ { "query_string" : { "query" : "?", "fields" : [ "name" ] } }, { "query_string" : { "query" : "?", "fields" : [ "price" ] } } ] } } }Or:findByNameOrPrice
{ "query" : { "bool" : { "should" : [ { "query_string" : { "query" : "?", "fields" : [ "name" ] } }, { "query_string" : { "query" : "?", "fields" : [ "price" ] } } ] } } }Is: findByName
{ "query" : { "bool" : { "must" : [ { "query_string" : { "query" : "?", "fields" : [ "name" ] } } ] } } }Not: findByNameNot
{ "query" : { "bool" : { "must_not" : [ { "query_string" : { "query" : "?", "fields" : [ "name" ] } } ] } } }Between: findByPriceBetween
{ "query" : { "bool" : { "must" : [ { "range" : { "price" : {"from" : ?, "to" : ?, "include_lower" : true, "include_upper" : true } } } ] } } }LessThan: findByPriceLessThan
{ "query" : { "bool" : { "must" : [ { "range" : { "price" : {"from" : null, "to" : ?, "include_lower" : true, "include_upper" : false } } } ] } } }LessThanEqual: findByPriceLessThanEqual
{ "query" : { "bool" : { "must" : [ { "range" : { "price" : {"from" : null, "to" : ?, "include_lower" : true, "include_upper" : true } } } ] } } }GreaterThan: findByPriceGreaterThan
{ "query" : { "bool" : { "must" : [ { "range" : { "price" : {"from" : ?, "to" : null, "include_lower" : false, "include_upper" : true } } } ] } } }GreaterThanEqual: findByPriceGreaterThan
{ "query" : { "bool" : { "must" : [ { "range" : { "price" : {"from" : ?, "to" : null, "include_lower" : true, "include_upper" : true } } } ] } } }Before: findByPriceBefore
{ "query" : { "bool" : { "must" : [ { "range" : { "price" : {"from" : null, "to" : ?, "include_lower" : true, "include_upper" : true } } } ] } } }After: findByPriceAfter
{ "query" : { "bool" : { "must" : [ { "range" : { "price" : {"from" : ?, "to" : null, "include_lower" : true, "include_upper" : true } } } ] } } }Like: findByNameLike
{ "query" : { "bool" : { "must" : [ { "query_string" : { "query" : "?*", "fields" : [ "name" ] }, "analyze_wildcard": true } ] } } }StartingWith: findByNameStartingWith
{ "query" : { "bool" : { "must" : [ { "query_string" : { "query" : "?*", "fields" : [ "name" ] }, "analyze_wildcard": true } ] } } }EndingWith: findByNameEndingWith
{ "query" : { "bool" : { "must" : [ { "query_string" : { "query" : "*?", "fields" : [ "name" ] }, "analyze_wildcard": true } ] } } }Contains/Containing: findByNameContaining
{ "query" : { "bool" : { "must" : [ { "query_string" : { "query" : "*?*", "fields" : [ "name" ] }, "analyze_wildcard": true } ] } } }In (when annotated as FieldType.Keyword): findByNameIn(Collection<String>names)
{ "query" : { "bool" : { "must" : [ { "bool" : { "must" : [ { "terms" : {"name" : ["?","?"]} } ] } } ] } } }In: findByNameIn(Collection<String>names)
{ "query": {"bool": {"must": [{"query_string":{"query": "\"?\" \"?\"", "fields": ["name"]}}]}}}NotIn (when annotated as FieldType.Keyword): findByNameNotIn(Collection<String>names)
{ "query" : { "bool" : { "must" : [ { "bool" : { "must_not" : [ { "terms" : {"name" : ["?","?"]} } ] } } ] } } }NotIn: findByNameNotIn(Collection<String>names)
{ "query": { "bool": { "must": [{ "query_string": { "query": "NOT(\"?\" \"?\")", "fields": ["name"] } }] } } }Near: findByStoreNear
暂不支持
True: findByAvailableTrue
{ "query" : { "bool" : { "must" : [ { "query_string" : { "query" : "true", "fields" : [ "available" ] } } ] } } }False: findByAvailableFalse
{ "query" : { "bool" : { "must" : [ { "query_string" : { "query" : "false", "fields" : [ "available" ] } } ] } } }OrderBy: findByAvailableTrueOrderByNameDesc
{ "query" : { "bool" : { "must" : [ { "query_string" : { "query" : "true", "fields" : [ "available" ] } } ] } }, "sort":[{ "name":{"order":"desc"} }] }