# Java 集合底层原理剖析
# 1. Java 集合介绍
Java 集合是一个存储相同类型数据的容器,类似数组,集合可以不指定长度,但是数组必须指定长度。集合类主要从 Collection 和 Map 两个根接口派生出来,比如常用的 ArrayList、LinkedList、HashMap、HashSet、ConcurrentHashMap 等等。
Collection 根接口框架简化结构图(线程不安全):
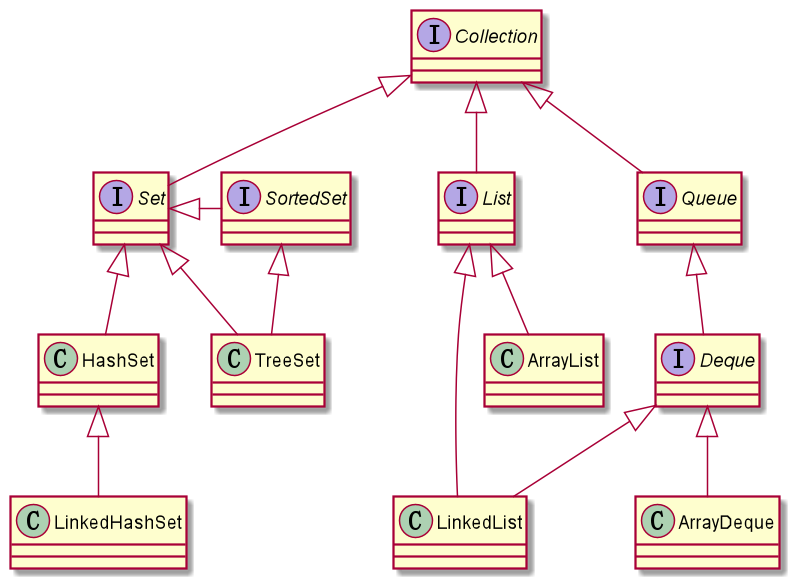
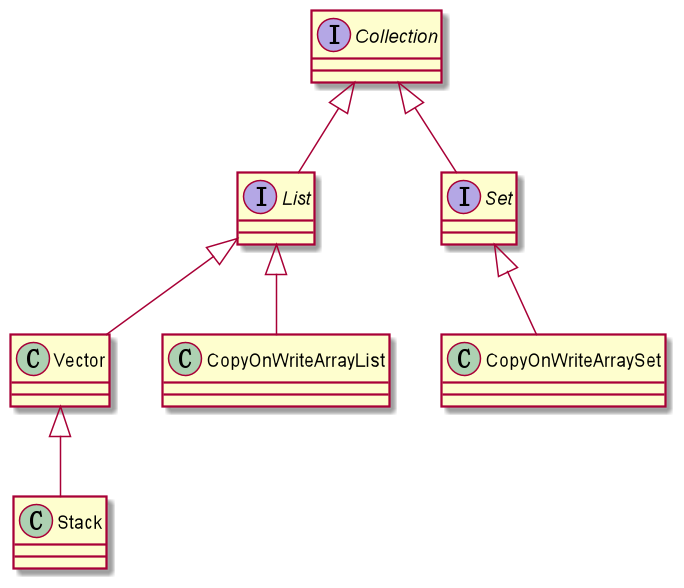
Collection 根接口框架简化结构图(线程安全):
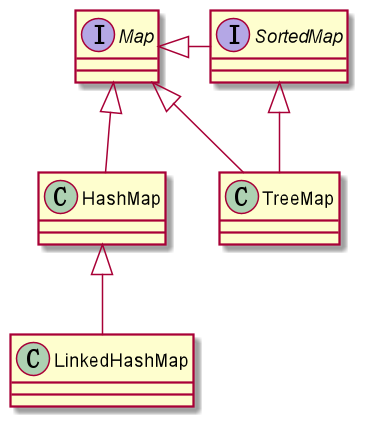
Map 根接口框架简化结构图(线程不安全):
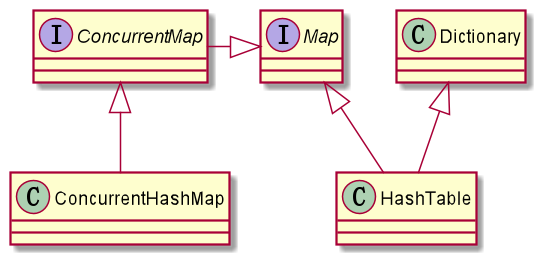
Map 根接口框架简化结构图(线程安全):
JDK 中的集合框架首次出现在 1.0 版本,随后在 1.2 和 1.5 版本中有较大更新。其它版本的更新对于集合框架的更新都是小更新。
大体上,这三个版本的主要 feature 在于:
- Plan A:线性安全实现。
- Plan B:线性不安全实现。性能更好。
- Plan A plus:线性安全实现的另一种方案。用来和 Plan A “打擂台”。
# 2. List
List 体系在 JDK 1.0 的时候就已经存在了。作为它的兄弟,Set 接口反而是在 JDK 1.2 中才被补充进集合框架。
Collection (jdk 1.0)
└── List (jdk 1.0)
|── Vector / Stack (jdk 1.0)
|── ArrayList (jdk 1.2)
|── LinkedList (jdk 1.2)
└── CopyOnWriteArrayList (jdk 1.5)
# 2.1 Vector
Vector 实现的是数据结构领域中的『基于数组实现的线性表』。线性表也叫『向量』,所以它用上了 vector 这个单词。
Vector 诞生于 JDK 1.0 时代,实现的是 List 接口。底层是通过『动态数组』实现的。『动态数组』是指当数组容量不足以存放新的元素时,会创建新的数组,然后把原数组中的内容复制到新数组。
特征:
- 查询效率高、插入、删除效率低,因为需要移动元素;
- 线程安全。
- 允许添加 null 值,且允许添加多个;
- 未指定初始化大小时,默认的大小为 10 。每次扩容时变为原来大小的 2 倍。在批量添加时,如果扩容后仍不够,则按实际需要扩容。
# 2.2 Stack
Stack 实现的是数据结构中的『基于数组实现的栈』。
Stack 诞生于 1.0 时代,它继承自 Vector ,间接实现了 List 接口,但它的核心逻辑还是『栈』。
注意事项:
- 『非线性安全的栈』在 Java 集合框架中都是通过使用『双端队列』来实现功能。
# 2.3 ArrayList
ArrayList 实现的是数据结构领域中的『基于数组实现的线性表』。这和 Vector 是一样的。
ArrayList 诞生于 JDK 1.2 ,实现的是 List 接口。它的底层是通过『动态数组』实现的。
特征:
- 查询效率高、插入、删除效率低,因为需要移动元素;
- 线程不安全。
- 允许添加 null 值,且允许添加多个;
- 未指定初始大小时,默认大小为 0 。 扩容时容量变为原大小的 1.5 倍。批量添加时,如果扩容后仍不够,则按实际需要扩容。
# 2.4 LinkedList
LinkedList 实现的是数据结构领域中的『基于链表实现的线性表』。
LinkedList 和 ArrayList 是 “双胞胎” ,都是诞生于 JDK 1.2,实现类 List 接口。LinkedList 底层使用『双向链表』实现。
特性:
- 插入和删除效率高,查询效率低;顺序访问会非常高效,而随机访问效率(比如 get 方法)比较低;
- 线程不安全;
- 允许添加 null 值,且允许添加多个;
- LinkedList 不存在扩容问题。
- LinkedList 除了实现 List 接口,它还『多』实现了 Deque 接口。
# 2.5 CopyOnWriteArrayList
CopyOnWriteArrayList 实现的是数据结构领域中的『基于数组实现的线性表』。这和 Vector、ArrayList 是一样的。
CopyOnWriteArrayList 是诞生于 JDK 1.5 ,实现了List 接口。底层通过『动态数组』实现,并且提供了不同于 Vector 的线程安全实现:
写操作(add、set、remove 等等)上锁,并且把原数组拷贝一份出来,然后在新数组进行写操作,操作完后,再将原数组引用指向到新数组。
读操作不加锁,读的时原数组,因此可能读到旧的数据。比如正在执行读操作时,同时有写操作在进行,遇到这种场景时,就会都到旧数据。
特性:
- 线程安全;
- 查询效率高;写操作,需要拷贝数组,比较消耗内存和时间;
- 允许添加 null 值,且允许添加多个;
- 不能用于实时读的场景,因为读取到数据可能是旧的,可以保证最终一致性(不保证实时一致性)。
补充
JDK 1.5 还提供了 Collections.synchronizedList(List list) 来获得线程安全版的 List 。
# 2.6 ArrayList、LinkedList、Vector 三者的区别
核心区别:
| List 的实现 | 线程安全 | 底层实现 | 默认初始容量 扩容系数 |
|---|---|---|---|
| Vector(JDK 1.0) | Yes | 动态数组 | x 2 |
| ArrayList(JDK 1.2) | No | 动态数组 | x 1.5 |
| LinkedList(JDK 1.2) | No | 双向链表 | 无 |
其它区别:
# 3. Map
Map 体系在 JDK 1.0 的时候就已经存在了,在当时是集合框架的 2 条腿之一(另一条腿是 List 体系。这个时候还没有 Set 体系,Set 体系 1.2 才出现)。
Map (jdk 1.0)
|── Hashtable (jdk 1.0)
|── TreeMap (jdk 1.2)
|── HashMap (jdk 1.2)
| └── LinkedHashMap (jdk 1.4)
└── ConcurrentHashMap (jdk 1.5)
Map 结构是以 key-value 键值对形式存储数据。在数据结构领域,这种结构也被称作『字典(Dictionary)』。
另外,在数据结构领域,哈希表和哈希集是同一种结构的 2 种不同称呼,所以,在 JDK 里面 HashTable 和 HashMap 这两个单词都被用上了。
# HashTable
Hashtable 对应的是数据结构中的『散列表』结构。从直译角度来看,Hashtable 这个单词要比 Hashmap 更地道。
Hashtable 诞生于 JDK 1.0 ,实现了 Map 接口。底层使用『数组+链表』实现。
补充
Hashtable 这种解决 hash 冲突的方式被称为『链地址法』,也叫拉链法。
特性:
- 线程安全。
- 查询、插入、删除效率都高(集成了多方特性)
- key 和 value 都不允许为 null。
- Hashtable 默认的初始大小为 11 ,之后每次扩充为原来的 2 倍;
- 除了实现 Map 接口,Hashtable 还继承了 Dictionary 类。这是它的兄弟姐妹们所没有的特征。
# HashMap
Hashmap 对应的是数据结构中的『散列表』结构。
从计算机词汇的翻译上看,hashtable 和 hashmap 是一回事(当然底层实现原理不同)。
HashMap 是诞生于 JDK 1.2,实现了 Map 接口。以前,Hashmap 和 Hashtable 的底层数据结构是一样的,都是『数组+链表』。但是在 JDK 8 中 Hashmap 的底层实现有升级:『数组+链表』or『数组+红黑树』:
数据量不大的时候,底层使用『数组+链表』;
当数据量增加到一定程度,就变为 数组+红黑树』。链表长度
>=8时,并且同时数组的长度>=64。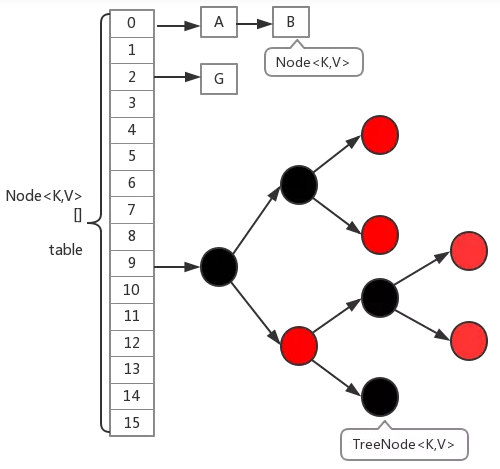
特性
线程不安全。
查询、插入、删除效率都高(集成了多方特性)
允许 null 的键值对;
初始容量是 16,每次扩容都是变为原来大小的 2 倍;
用到了一个编程小技巧:用位运算(&)来代替取模运算(%)
当 b 的值为 2^n 时,
a % b和a & (b-1)的值相等。这样效率更高,并且可以解决负数问题(负数模运算取余,余数应该始终为正数)。
# ConcurrentHashMap
ConcurrentHashMap 对应的是数据结构中的『散列表』。
ConcurrentHashMap 诞生于 JDK 1.5 时代。它实现了 Map 接口。ConcurrentHashMap 和 HashMap 一样,底层使用『数组 + 链表 + 红黑树』实现。
另外,在 Java 8 版本中,ConcurrentHashMap 有比较大的变动(更新升级),采用 CAS + Synchronized 实现锁操作,因此,性能上要好于 JDK 1.0 时代的 Hashtable 。
特性:
- 线程安全。
- 查询、插入、删除效率都高(集成了多方特性)
# HashMap、Hashtable、ConccurentHashMap 三者的区别
| List 的实现 | 历史 | 线程安全 | 底层数据结构 |
|---|---|---|---|
| Hashtable | JDK 1.0 | Yes(Synchronized 实现) | 数组 + 链表 |
| HashMap | JDK 1.2 | No | 数组 + 链表 + 红黑树 |
| ConccurentHashMap | JDK 1.5 | Yes(CAS + Synchronized 实现) | 数组 + 链表 + 红黑树 |
其它小细节:
| List 的实现 | null-key | null-value |
|---|---|---|
| Hashtable | 不允许 | 不允许 |
| HashMap | 允许 | 允许 |
| ConccurentHashMap | 不允许 | 不允许 |
# TreeMap
TreeMap 对应的是数据结构中的『散列表』。
TreeMap 和 HashMap 一样,也是诞生于 JDK 1.2,实现的是 Map 接口的实现类,底层使用『红黑树』实现。
另外,TreeMap 除了实现了 Map 接口,它还实现了 SotredMap 接口,意味着可以排序,是一个有序的集合,你添加进 TreeMap 中的数据会被它自动排序。
特性:
- 线程不安全;
- 查询、插入、删除效率都比较高。
# LinkedHashMap
- 线程不安全
- 底层使用『数组 + 链表 + 红黑树』实现
LinkedHashMap 并不是在关键节点添加进集合框架的,它是在 JDK 1.4 的时候添加进集合框架的。看起来像个补丁。
LinkedHashMap 继承自 HashMap ,它在 HashMap 的基础上用链表额外去『串』起了所有的节点,这样就能记录下添加到 LinkeHashMap 中的数据的添加顺序,从而保证了迭代顺序和添加顺序的一致。
# HashMap 与 TreeMap 的区别
关键性区别:
| Map 的实现 | 线程安全 | 底层实现 |
|---|---|---|
| HashMap (JDK 1.2) | No | 数组 + 链表 + 红黑树,无序 |
| TreeMap (JDK 1.2) | No | 红黑树,有序 |
其它小区别:
| Map 的实现 | null-key | null-val | 默认初始容量 | 扩容系数 |
|---|---|---|---|---|
| HashMap (JDK 1.2) | 允许 | 允许 | 16 | x2 |
| TreeMap (JDK 1.2) | 不允许 | 不允许 | 无 | 无 |
另外,相较而言,Hashmap 效率略高,Treemap 效率略低。
其实从使用思路上看,它们两个侧重点完全不同:HashMap 的侧重点是 hash ,虽然在 1.8 中用到了红黑树,但是本质上是对 1.8 以前的链表方案的升级而已(实际上,并非非用树不可);而 TreeMap 的侧重点就是 tree,可以想象,即便底层不是使用的红黑树,其作者也会使用其它树结构(例如 AVL 树)。
# 4. Set
整个 Set 体系是在第二波(JDK 1.2)才被添加进集合框架中的,看起来,它好似 List 的兄弟,但是实际上,它出现地要比 List(和 Map)晚。
由于在集合框架的第一波(JDK 1.0)中并没有 Set 体系,因此 Set 体系在线程安全的实现上,就没有想 List 和 Map 一样『走弯路』:
JDK 1.2 中引入是 Set 的线程不安全实现;
在 JDK 1.5(J.U.C)中引入的是 Set 的线程安全实现。
Set (jdk 1.2)
|── TreeSet (jdk 1.2)
|── HashSet (jdk 1.2)
| └── LinkedHashSet (jdk 1.4)
└── CopyOnWriteArraySet (jdk 1.5)
一个既有意思又重要的现象:虽然 Set 看起来和 List 更亲(都是 Collection 接口的子接口),但是 Set 的各种实现类底层却是『利用 Map』实现的自己的功能。
# HashSet
- 线程不安全
- 底层用 HashMap 实现。根本结构是数组+链表+红黑树。
HashSet 是用来存储没有重复元素的集合类,并且是无序的。或者说,你可以添加重复元素,但是从第二次添加开始,你加了也白加。
由于 HashSet 底层利用的是 HashMap 实现,因此你添加到 HashSet 中的值,都被它添加到一个 HashMap 中作了 key:
- 由于 HashMap 的 key 不能重复,所以 HashSet 中的值自然也就是不能重复的;
- 由于 HashMap 允许 null-key,所以 HashSet 中也可以添加一个 null 。
使用场景:去重、不要求顺序
# TreeSet
- 线程不安全
- 底层使用 TreeMap 实现,因此根本结构是『红黑树』。
TreeSet 除了实现 Set 接口,它还实现了 SortedSet 接口,意味着可以排序,它是一个有序并且没有重复的集合类。TreeMap 是有序的,因此 TreeSet 自然也就是有序的。
由于 TreeSet 底层利用的是 TreeMap 实现,因此你添加到 TreeSet 中的值,都被它添加到一个 TreeMap 中作了 key:
TreeMap 是内部有序的,TreeSet 自然也就是内部有序的;
TreeMap 不允许添加 null-key,TreeSet 自然也就不允许添加 null 值。
TreeSet 支持两种排序方式:自然排序(默认)和自定义排序。
使用场景:去重、要求排序
# LinkedHashSet
- 线程不安全
- HashSet 的子类,底层利用了 LinkedHashMap,因此根本结构是『数组+链表+红黑树』。
由于 LinkedHashSet 底层利用了 LinkedHashMap,因此:
- LinkedHashMap 是 JDK 1.4 中出现的;LinkedHashSet 自然也是 JDK 1.4 才出现的;
- LinkedHashMap 能记录元素的添加次序,LinkedHashSet 自然也就能记录元素的添加次序。
使用场景:去重、需要保证插入或者访问顺序
# HashSet、TreeSet、LinkedHashSet 的区别
历史发展层面:
| Set 的实现 | 诞生 |
|---|---|
| HashSet | JDK 1.2 |
| TreeSet | JDK 1.2 |
| LinkedHashSet | JDK 1.4 |
线程安全层面:他们三个都是线程不安全的。
底层数据结构:
| Set 的实现 | 底层实现 |
|---|---|
| HashSet | 利用了 HashMap,去重 |
| TreeSet | 利用了 TreeMap,去重 + 内部有序 |
| LinkedHashSet | 利用了 LinkedHashMap,去重 + 外部有序 |
# CopyOnWriteArraySet
- 线程安全
- 底层利用的是 CopyOnWriteArrayList
CopyOnWriteArraySet 是 JDK 1.5(J.U.C)引入的 Set 接口的线程安全实现。
特征:线程安全读多写少,比如缓存不能存储重复元素。
# 5. Queue
Queue 体系比较『新』。Queue 接口在 JDK 1.5 才引入到 JDK 集合框架体系,它的子接口 Deque 接口在 JDK 1.6 的时候才补充进 JDK 。
Deque 继承自 Queue ,是一个既可以在头部操作元素,又可以为尾部操作元素,俗称为双端队列。
在数据结构领域,Queue 是一个先入先出(FIFO)的集合。
在集合框架中它分为 3 大类:
非阻塞队列:普通队列(Queue、Deque)
阻塞队列(BlockingQueue)
其它队列:主要是优先级队列 (PriorityQueue、PriorityBlockingQueue)
# 非阻塞队列(普通队列)
非阻塞队列(普通队列)主要指的是 Queue 接口(JDK 1.5)和 Deque 接口(JDK 1.6)的直接实现类。
Collection
└── Queue
|── ConcurrentLinkedQueue 基于链表,线程安全
└── Deque
|── ArrayDeque 基于动态数组,线程不安全
|── LinkedList 基于链表,线程不安全
└── ConcurrentLinkedDeque 基于链表,线程安全
Queue 接口定义(引入)的方法包括:
| Throws exception | Returns special value | |
|---|---|---|
| Insert | add(e) | offer(e) |
| Remove | remove() | poll() |
| Examine | element() | peek() |
Deque 接口定义(引入)的方法包括:
| Throws exception | Special value | Throws exception | Special value | |
|---|---|---|---|---|
| Insert | addFirst(e) | offerFirst(e) | addLast(e) | offerLast(e) |
| Remove | removeFirst() | pollFirst() | removeLast() | pollLast() |
| Examine | getFirst() | peekFirst() | getLast() | peekLast() |
在引入 Deque 接口之后,JDK 很是器重它,一方面 Deque 的功能涵盖了 Queue 的功能,另一方面,数据结构中的『栈』和『队列』都可以通过 Deque 统一实现。
Queue VS Deque:
| Queue Method | Equivalent Deque Method |
|---|---|
| add(e) | addLast(e) |
| offer(e) | offerLast(e) |
| remove() | removeFirst() |
| poll() | pollFirst() |
| element() | getFirst() |
| peek() | peekFirst() |
Stack VS Deque:
| Stack Method | Equivalent Deque Method |
|---|---|
| push(e) | addFirst(e) |
| pop() | removeFirst() |
| peek() | peekFirst() |
# 阻塞队列
阻塞队列在队列功能的基础上提供了『阻塞当前线程』的能力:在空队列获取元素时、或者在已存满队列存储元素时,都会被阻塞当前线程。阻塞队列全部都是线程安全的。
阻塞队列体系:
Collection
└── Queue
|── BlockingQueue
| |── LinkedBlockingQueue 基于链表
| |── ArrayBlockingQueue 基于动态数组
| └── SynchronousQueue 基于 CAS 的阻塞队列。 |
└── Deque
└── BlockingDeque
└── LinkedBlockingDeque 基于链表,双端队列
BlockingQueue 接口引入了一套新的 API,它和 Queue 的那套 API 是独立的,互不影响,不要调用错了。
| Throws exception | Special value | Blocks | Times out | |
|---|---|---|---|---|
| Insert | add(e) | offer(e) | put(e) | offer(e, time, unit) |
| Remove | remove() | poll() | take() | poll(time, unit) |
| Examine | element() | peek() | not applicable | not applicable |
# 其它队列(优先级队列)
PriorityQueue 是基于最小二叉堆实现的数据结构。内部以自然顺序排序。
常见的 PriorityQueue 是线程非安全的,PriorityBlockingQueue 是线程安全的。它俩底层数据结构是一样的。
Collection
└── Queue
|── PriorityQueue
└── BlockingQueue
└── PriorityBlockingQueue
# 6. 集合框架的线程安全问题
很多复杂/混乱的问题从历史的角度来看会非常的清晰。
集合的线程安全问题指的是如果两个线程同时操作同一个集合对象出现 ConcurrentModificationException 异常的情况。
| 接口 | 1.0 | 1.1 | 1.2 |
|---|---|---|---|
| List | Vector | ||
| Map | Hashtable | ||
| Set | 无 |
# JDK 1.0 时代的集合类
JDK 1.0 时代『一步到位』地将各种集合都是现成了线程安全版。所以,这个时代出现的 Vector(List 接口的实现)、Hashtable(Map 接口的实现)都是线程安全的。
这里需要注意的是 Set 接口(及其实现类)是从 1.2 版本开始才出现的,1.2 之前并没有。
# JDK 1.2 时代的集合类
线程安全的代价就是降低了性能。『线程安全』和『高性能』没有哪个是标准答案,它们应该是 Plan A 和 Plan B 的关系,选哪个决定权应该在使用者的手里。
如果说,1.0 提供的是 Plan A ,那么 1.2 提出的就是 Plan B 。简单来说,1.0 的 List 和 Map 接口的实现类都是线程安全的;1.2 的 List 和 Map 接口的实现类都是非线程安全的。
# JDK 1.2 时代的集合类的其它改动
除了提供 List 和 Map 的 Plan B 之外,1.2 时代还有一个比较大的升级:出现了 Set 接口(及其实现类)。
Set 体系一出现就是 Plan B 版本,因此,常见的实现类 HashSet 和 TreeSet 都是非线程安全的。
另外,JDK 1.2 除了提出了非线性安全版的实现外,对线性安全版的实现还做出了『补充』:JDK 1.2 中提供的集合工具类 Collections ,有如下的一批方法:
Collections.synchronizedCollection();
Collections.synchronizedList();
Collections.synchronizedSet();
Collections.synchronizedMap();
这些方法接受非线程安全的 List、Set、Map 对象,返回与之对应的线程安全版的 List、Set、Map 对象。为了避免命名带来的记忆负担,官方还很贴心地将这些线程安全版地实现类写成了内部类的形式,你只需要以面向接口编程的思想去使用它们就行,而不必在意它们的名字叫什么(当然,看源码还是能看到的)。
所以,如果你需要线性安全的 List 和 Map,除了,使用 JDK 1.0 版中的哪些实现外,还可以用上面的方式获得它们。
# JDK 1.2 的未尽工作
JDK 1.2 在 JDK 1.0 / 1.1 的基础上完善、更新了 Collection 和 Map 体系下的接口和实现类。但是它的工作并未完全结束。体现在两个方面:
截止到 1.2,集合体系主要体现在 List、Set 和 Map 的功能,但是对于数据结构领域中的其它结构,它的功能并不丰富。例如常见的队列(Queue)结构就没有。
截止到 1.2,了解决集合的线程安全问题的方案简单粗暴(提供的同步集合类,不允许同时存在多个线程操作同一个集合对象)。而有些场景下需要在多线程同时访问同一个线程对象时还要保证线程安全性(这个要求就很高了)。
在 JDK 1.2 之后的 JDK 版本中陆陆续续还有对集合框架体系的内容进行修补完善,直到 JDK 1.5 中提出了 J.U.C,它里面包含了提供并发能力的集合实现类,至此 JDK 中的集合框架算是基本完善成型,再有的工作就是零零碎碎的小修补、小完善了。
不过,不像 JDK 1.2 这样对集合框架整体进行更新,后续版本中对于集合框架的修补完善不再是版本更新的核心功能,因此这些修改并非各个版本升级时的宣传重点,直到 JDK 1.5 的 J.U.C 中又作为 feature 宣传了一下。
# Queue 和 Stack
同样是作为常见的 2 中特殊的线性表结构, Queue 和 Stack 的命运在 JDK 中十分不同。
Stack 是类,继承自 Vector 类,是 List/Collection 接口的间接实现类,它是 JDK 1.0 出现的最早的一批成员。
Queue 是接口,直接继承自 Collection 接口,在 JDK 1.5 才出现!而它的一个子接口 Deque(双端队列)到 JKD 1.6 时才出现。
Deque 的接口的常用实现类有两个:
ArrayDeque,底层使用数组实现 Deque 接口要求的方法;
LinkedList,底层使用链表实现 Deque 接口要求的方法。注意,从名字上看,你很容易忽视掉它。
它们都是非线程安全的。
这里有两个小问题:
JDK 没有直接提供 Stack 的非线性安全版本。在它的代码注释中,官方建议使用 Deque 接口的实现类来当作 statck 使用。
Collections 工具类中并没有直接的
.synchronizedDeque()方法,这就导致没有直接的便捷的方式获得线程安全版的队列和栈对象。
因此对栈和队列的使用还是要比 List、Set 和 Map 要麻烦一点。不过,不排除后续的 JDK 升级中会完善改进这两个问题。
← Java 的引用和对象 反射 →